📕 RUSpellRU
The dataset is a part of spellcheck_punctuation_benchmark:
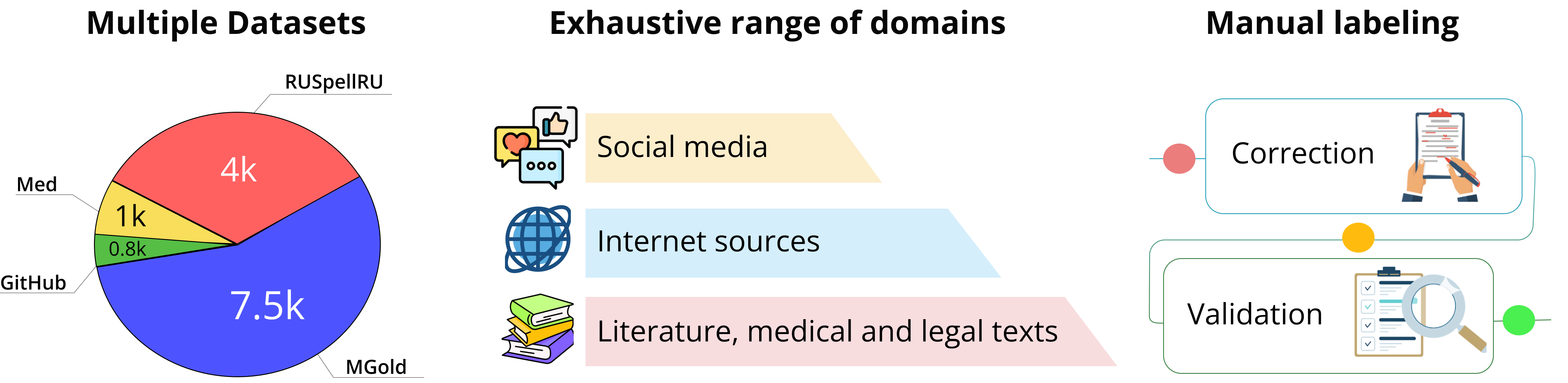
The Benchmark includes four datasets, each of which consists of pairs of sentences in Russian language. Each pair embodies sentence, which may contain spelling and punctuation errors, and its corresponding correction. Datasets were gathered from various sources and domains including social networks, internet blogs, github commits, medical anamnesis, literature, news, reviews and more.
All datasets were passed through two-stage manual labeling pipeline. The correction of a sentence is defined by an agreement of at least two human annotators. Manual labeling scheme accounts for jargonisms, collocations and common language, hence in some cases it encourages annotators not to amend a word in favor of preserving style of a text.
The latter does not apply to punctuation. Punctuation signs are rigorously marked in accordance to the rules of the Russian punctuation system.
Table of contents
Dataset Description
Repository: SAGE
Paper: EACL 2024
Point of Contact: nikita.martynov.98@list.ru
Dataset Summary
The dataset origins from RuSpellEval competition. The texts were gathered from LiveJournal and annotated by linguistic experts in two rounds. RUSpellRU amounts for 4k sentence pairs that represented Social Networks and Internet Blogs text domains.
Supported Tasks and Leaderboards
Task: automatic spelling correction.
Metrics: https://www.dialog-21.ru/media/3427/sorokinaaetal.pdf.
Languages
Russian.
Dataset Structure
Data Instances
Size of downloaded dataset files: 3.65 Mb
Size of the generated dataset: 1.31 Mb
Total amount of disk used: 4.96 Mb
An example of “train” / “test” looks as follows
{
"source": "очень классная тетка ктобы что не говорил.",
"correction": "очень классная тетка кто бы что ни говорил",
}
Data Fields
source: a string feature
correction: a string feature
domain: a string feature
Data Splits
train |
test |
|
|---|---|---|
RUSpellRU |
2000 |
2008 |
Considerations for Using the Data
Discussion of Biases
We clearly state our work’s aims and implications, making it open source and transparent. The data will be available under a public license. As our research involved anonymized textual data, informed consent from human participants was not required. However, we obtained permission to access publicly available datasets and ensured compliance with any applicable terms of service or usage policies.
Other Known Limitations
The data used in our research may be limited to specific domains, preventing comprehensive coverage of all possible text variations. Despite these limitations, we tried to address the issue of data diversity by incorporating single-domain and multi-domain datasets in the proposed research. This approach allowed us to shed light on the diversity and variances within the data, providing valuable insights despite the inherent constraints.
We primarily focus on the Russian language. Further research is needed to expand the datasets for a wider range of languages.
Additional Information
Future plans
We are planning to expand our benchmark with both new Russian datasets and datasets in other languages including (but not limited to) European and CIS languages. If you would like to contribute, please contact us.
Dataset Curators
Nikita Martynov nikita.martynov.98@list.ru (Spellcheck Punctuation Benchmark)
Licensing Information
All our datasets are published by MIT License.
Citation Information
@inproceedings{martynov2023augmentation,
title={Augmentation methods for spelling corruptions},
author={Martynov, Nikita and Baushenko, Mark and Abramov, Alexander and Fenogenova, Alena},
booktitle={Proceedings of the International Conference “Dialogue},
volume={2023},
year={2023}
}
@inproceedings{martynov-etal-2024-methodology,
title = "A Methodology for Generative Spelling Correction via Natural Spelling Errors Emulation across Multiple Domains and Languages",
author = "Martynov, Nikita and
Baushenko, Mark and
Kozlova, Anastasia and
Kolomeytseva, Katerina and
Abramov, Aleksandr and
Fenogenova, Alena",
editor = "Graham, Yvette and
Purver, Matthew",
booktitle = "Findings of the Association for Computational Linguistics: EACL 2024",
month = mar,
year = "2024",
address = "St. Julian{'}s, Malta",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.findings-eacl.10",
pages = "138--155",
abstract = "Large language models excel in text generation and generalization, however they face challenges in text editing tasks, especially in correcting spelling errors and mistyping.In this paper, we present a methodology for generative spelling correction (SC), tested on English and Russian languages and potentially can be extended to any language with minor changes. Our research mainly focuses on exploring natural spelling errors and mistyping in texts and studying how those errors can be emulated in correct sentences to enrich generative models{'} pre-train procedure effectively. We investigate the effects of emulations in various text domains and examine two spelling corruption techniques: 1) first one mimics human behavior when making a mistake through leveraging statistics of errors from a particular dataset, and 2) second adds the most common spelling errors, keyboard miss clicks, and some heuristics within the texts.We conducted experiments employing various corruption strategies, models{'} architectures, and sizes in the pre-training and fine-tuning stages and evaluated the models using single-domain and multi-domain test sets. As a practical outcome of our work, we introduce SAGE (Spell checking via Augmentation and Generative distribution Emulation).",
}