📊 SBSC
We implemented two methods for spelling corruption. Statistic-based Spelling Corruption (SBSC) aims to mimic human behaviour when making an error. While Augmentex relies on rule-based heuristics and common errors and mistypings especially those committed while typing text on a keyboard.
🚀 Both methods proved their effectiveness for spelling correction systems and celebrated substantial performance gains fully reported in our Paper.
SBSC is thoroughly described in our another Paper and in this 🗣️Talk.
Briefly, SBSC follows two simple steps:
🧠 Analyze errors, their type and positions in a source text;
✏️ Reproduce errors from the source text in a new sentence;
🧠 To analyze errors in a source sentence we need its corresponding correction in order to build Levenshtein matrix, traverse it back starting from the bottom right entry and determine the exact position and type of an error. We then aggregate all obtained statistics and normalize it to valid discrete distributions.
✏️ “Reproduce” step is even less complicated: we just sample number of errors per sentence, their types and relative positions from corresponding distributions and apply them to a correct sentence.
As stated, you need a parallel dataset to “fit” SBSC. We provide a set of four datasets with natural errors covering exhaustive range of domains:
RUSpellRU: texts collected from LiveJournal, with manually corrected typos and errors;
MultidomainGold: examples from 7 text sources, including the open web, news, social media, reviews, subtitles, policy documents and literary works;
MedSpellChecker: texts with errors from medical anamnesis;
GitHubTypoCorpusRu: spelling errors and typos in commits from GitHub;
You can use them as simple as
import sage
from sage.spelling_corruption import SBSCConfig, SBSCCorruptor
from sage.utils import DatasetsAvailable
# Instantiate SBSC corruptor from a dataset with errors in medical anamnesis
config = SBSCConfig(
reference_dataset_name_or_path=DatasetsAvailable.MedSpellchecker.name,
reference_dataset_split="test"
)
corruptor = SBSCCorruptor.from_config(config)
… or you can initialize your SBSC from locally stored dataset:
import os
from sage.spelling_corruption import SBSCConfig, SBSCCorruptor
# Instantiate SBSC corruptor from a JFLEG dataset
config = SBSCConfig(
lang="en",
reference_dataset_name_or_path=os.path.join("data", "example_data", "jfleg"),
)
corruptor = SBSCCorruptor.from_config(config)
✅ To check how good SBSC actually approximates original errors, you can plot side-by-side graphs of original and synthetically generated distributions:

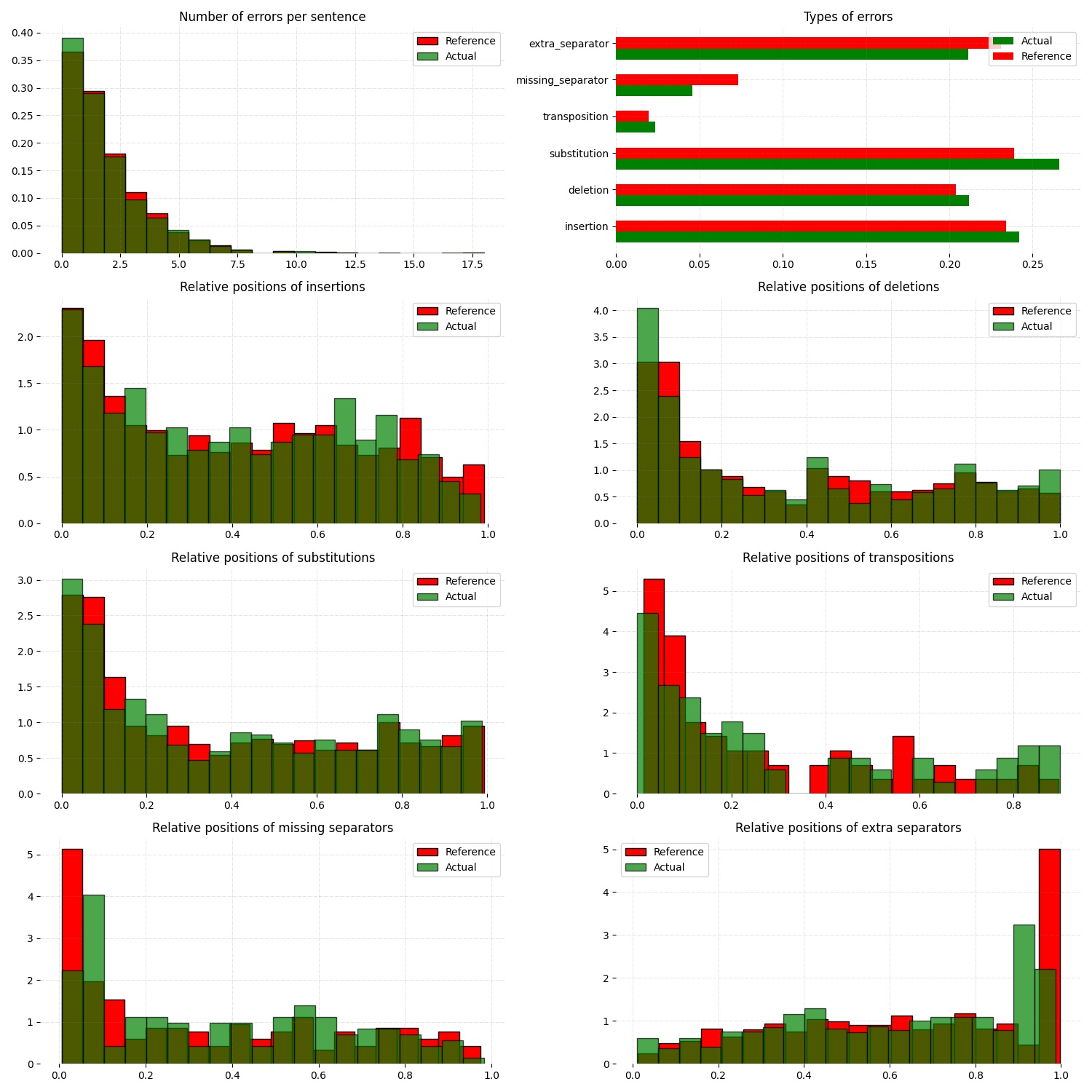
To access these graphs you can simply
from sage.utils import load_available_dataset_from_hf, draw_and_save_errors_distributions_comparison_charts
from sage.spelling_corruption.sbsc.labeler import process_mistypings
from sage.spelling_corruption import SBSCCorruptor
sources, corrections = load_available_dataset_from_hf("RUSpellRU", for_labeler=True, split="train")
ruspellru_stats, ruspellru_confusion_matrix, ruspellru_typos_cnt = process_mistypings(sources, corrections)
corruptor = SBSCCorruptor.from_default_config()
spoiled_sentences = corruptor.batch_corrupt(corrections)
sbsc_stats, sbsc_confusion_matrix, sbsc_typos_cnt = process_mistypings(spoiled_sentences, corrections)
draw_and_save_errors_distributions_comparison_charts(
actual_typos_cnt = sbsc_typos_cnt,
reference_typos_cnt=ruspellru_typos_cnt,
actual_stats=sbsc_stats,
reference_stats=ruspellru_stats,
path_to_save="ruspellru_sbsc.jpg"
)